文字コードと文字化け

Webページを見ているときに、意味不明な記号や漢字カタカナなどが表示されて読めない事があります。
これを俗にいう「文字化け」です。「記述した文字コード」と「解釈した文字コード」が異なることによって起こります。
「英語で書いていたのに、中国語で翻訳したらわけわからなくなった〜orz」みたいな感じです。現実ではあり得ませんけどw
文字化けとその解消方法
文字化けが発生するのは「文字コード」の解釈方法が違うのが原因です。もし文字化けが発生したときにはWebブラウザのエンコードメニューから適切な文字コードを選択することで直せます。
このエンコードメニューはWebブラウザによって違うのでGoogle先生に聞いてみてください!!
英語の文字コード
英語の文字コードは、ほとんどの場合「ASCIIコード(アスキーコード)」という番号が使用されます。
アスキーコードでは、数値の32が「空白」その後いくつかの記号が続き48~57が数字、またいくつかの記号が続き65から「A」「B」「C」と英語の大文字が割り当てられ、97から「a」「b」「c」と小文字が続くように割り当てられています。
ASCIIコードでは、文字コードは「0から255」の範囲の値です。この範囲は、2の8乗であり「1バイト(byte)」で表現します。
| 文字コード | 文字コードに対応する記号 |
|---|---|
| 0〜31 | 特殊記号 |
| 32〜47 | 空白・記号 |
| 48〜57 | 0〜9 |
| 58〜64 | 記号 |
| 65〜96 | 英語大文字 |
| 97〜122 | 英語小文字 |
日本語文字コード
日本語は文字の数が多いのでASCIIコードの「0から255」の範囲では表現できません。
そこで日本語の文字コードは「0から255」の範囲の場所を2つ使って2バイトで表現します。
日本語の文字コードは1種類ではなく「JIS」「シフトJIS」「EUC−JP」という3種類の文字コードがあります。
文字コードによって割り当てられる番号が違います。つまりページは「EUC−JP」で書かれているのにWebブラウザがそれを「シフトJIS」として解釈して表示すると対応する文字が違うので違う文字が表示されます、これが文字化けの原因です。
1.JISコード
日本規格協会(JIS)が定めたコード。全ての文字コードの基本となるものです。
2.シフトJISコード
JISコードをうまく計算することでASCIIコードでは未使用になっている番号に押し込めるように変換したものです。
Microsoft社によって考案された方式で、WindowsやMacなどで幅広く使用されています。
3.EUC-JP
EUC−JPもシフトJISと同様にASCIIコードで未使用になっている番号にJISコードを押し込めるようにした変換方式ですが計算方式が違います。LinuxなどのOSで使われています(ただし最近はUTF−8に置き換えられています)
UnicodeとUTF−8
昔はこれらの「JIS」「シフトJIS」「EUC−JP」でWebページを記述していました、しかし最近では「UTF−8」という文字コードで記述する機会が増えています。
「JIS」「シフトJIS」「EUC−JP」は、日本語独自の文字コードです。
それに対して「URF−8」は世界共通の文字コードである「Unicode(ユニコード)」をプログラムで扱いやすいよう少し変換した形式です。
世界共通の「Unicode」
Unicodeは「Unicode Consotium(ユニコードコンソーシアム)」という団体で策定されました。
Unicodeの策定では、世界各国の文字を集めて「同じ形の文字には同じコードをふる」という「文字の形と文字コードの統一化」が試みられました。例えば「東」という文字は日本・中国・韓国・ベトナムなどで使われています、そこでこの文字には同じ一つのコードを割り当てるといった具合です。
何となく同じような形だからコード(番号)は一緒でいいでしょ!っていうような考え方です。
Unicodeが制定されたのは1993年。登場してまもなく多くのソフトウェアがUnicodeをサポートするようになりました。
なぜなら今まで多言語に対応するには「日本語」「中国語」「韓国語」などそれぞれの文字コードを意識する必要があったのに対し、Unicodeを採用すれば全てに対応できるからです。
最近では、海外製のソフトでも日本語が使用できるものがほとんどですが、それは世界の開発者がUnicodeを使用するようになったからです。
UTF-8
実はUnicodeはほとんどそのまま使われることはなく「UTF-8」に変換されて使用されています。
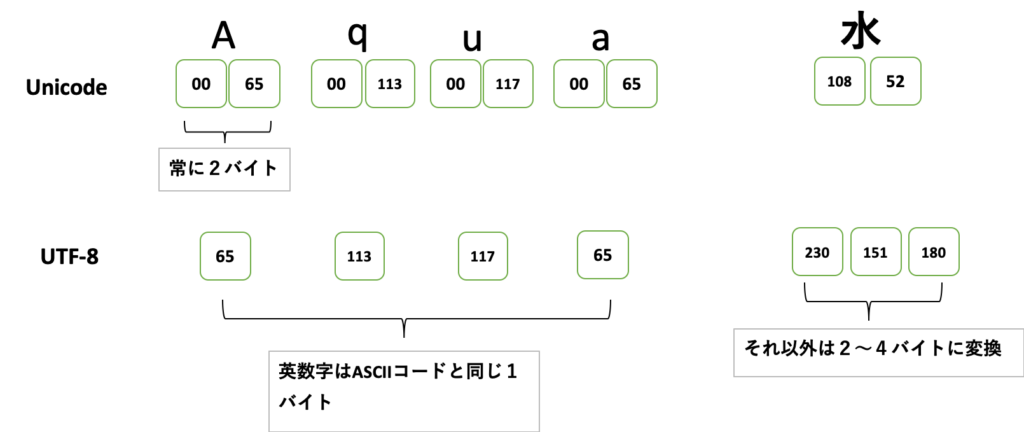
Unicodeは固定帳の文字コードで、どのような文字でも「2バイト」で表現します。これは英数字であっても例外ではありません英数字はASCIIコードで「1バイト」で表現できるので、Unicodeにすると、記憶する場所が倍必要になります。
しかもASCIIコードと互換性がないので今までASCIIコードを対象としていたプログラムを修正しなければならなくなります。
UTF-8はこれをうまく避けた表現方法です。UTF-8では英数字などASCIIコードと同じ1バイト、それ以外の文字は「2〜4バイト」の範囲で示すように変換します。
UTF-8が使われる理由
現在WebページはUTF-8で記述することがほとんどです。Webページ以外にも様々な場面でUTF−8が使われる事が増えてきました。
大きな理由は2つあります。
1.多言語を混在できる
UTF−8は全世界の文字が使えるUnicodeを変換したものであるため、各国の言語が混在可能です。例えば日本語のWebページに 韓国語や中国語などを混ぜて表示できます。
2.欧米圏のソフトをそのまま利用できる
シフトJISやEUC−JPは日本独自の仕様です。そのためこれらの文字コードを使用するにはソフト側の対応が必要です。
それに対してUTF-8は世界共通のコードです。最近ではほとんどの海外製ソフトがUTF-8に対応しているので、文字コードをUTF-8にすれば海外製ソフトであっても日本語を利用できます。
まとめ
いかがだったでしょうか、今現在で使用されている文字コードはUTF−8がとても多いです。文字コードなんて普段意識しないので文字化けしたときなんだこのページは何も読めない!ウイルスに感染してしまった!みたいに感じるかも知れませんが実際はウイルスとかは関係ありませんから安心してください。
ではでは
Follow me!