文字コードとは
時々、メール送られてきたけどよくわからない文字が表示されて全然読めない!なんてことはありませんか?
それは大体送り側と受けてで文字コードが違うからです、コンピュータは文字なんてわかりませんなので全て数値でで表現します。
一番ポピュラーな文字コード
文字コードの中で一番ポピュラーな文字コードはASCII(アスキー)です、下記がコード表です
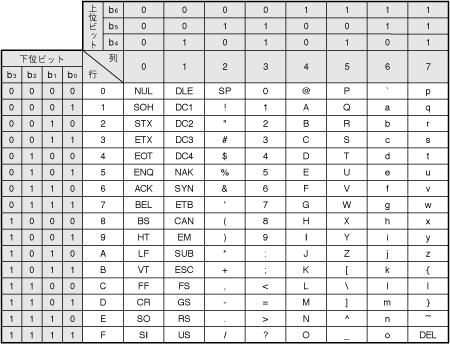
はい何がなんだかわかりませんね、よく見ると上位ビットと下位ビットと書いてあります。
これが意味があるんです例えば「A」という文字をASCIIコードで表すと「01000001」となります。さてやはり何がなんだかと言うことで下の図を見てみましょう
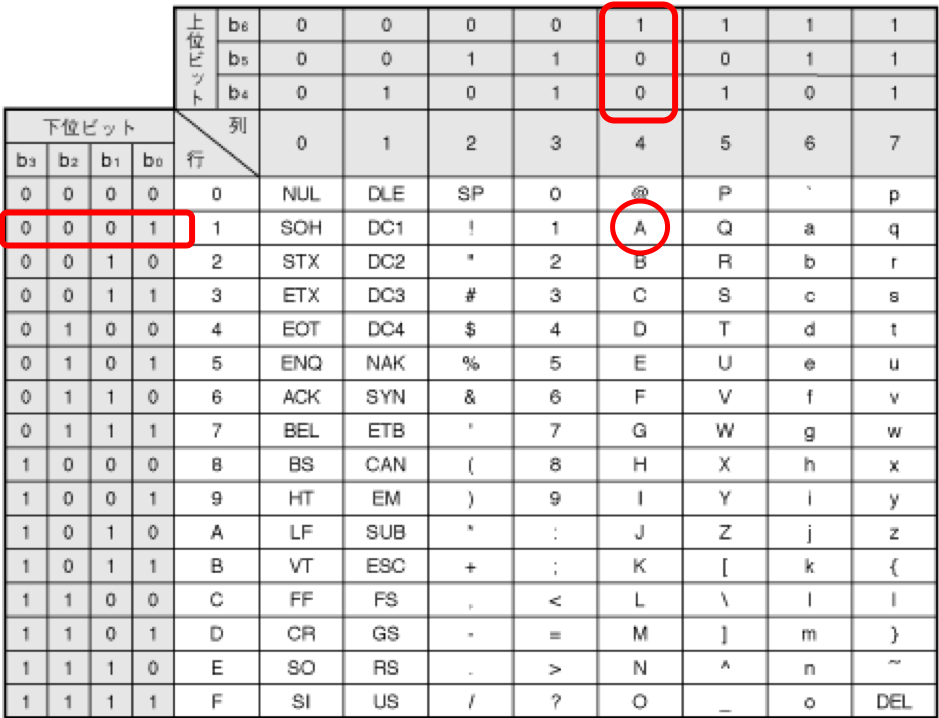
赤枠で囲ってある所に注目してください。左側から見ると下位ビットが「0001」となっておりますこれは
「01000001」の下4桁の「0001」を表しており同じように上位ビットが上3桁分を表しております。それを上から繋げると「1000001」となる訳です、あれ?1桁足りないって思いました?
実は頭1桁「0」の部分は実はパリティと言って誤りチェック用のビットなんです。簡単に言うと合っていれば「0」間違っていれば「1」みたいな感じです。
なんとなくASCIIがどのように文字を表現しているかわかったでしょうか。簡単ですがコンピュータが文字を理解する仕組みをASCIIコードを例に使い説明しました。
その他の文字コード
EBCDIC(エビシディック)
IBM社が定めた文字コードで、8ビットを使って1文字を表します。大型の汎用コンピュータなどで使用され ている
シフトJIS
ASCIIのコード体系の文字と混在させて使えるようになっている日本語文字コードです。ひらがなや感じ、カタカナなども扱えます。マイクロソフトのOSのWindowsでも使用されていて、1文字を2バイトで表します。
EUC
拡張UNIXコードとも呼ばれ、UNIXというOS上でよく使われる日本語文字コードで基本的には1文字を2バイトで表しますが、補助漢字などは3バイトで表す。
Unicode(ユニコード)
全世界の文字コードを一つに統一してしまえ!と各国のありとあらゆる文字を1つのコード体系で表そうとした文字コード。当初は1文字を2バイトで表す予定でしたがそれでは足りないということで、3バイト4バイトとどんどん拡張されています。
まとめ
色々なコンピュータが表す文字コードを説明してきましたが実はほんとにごく一部で実際はたくさんあります。
この記事で紹介した文字コードは代表的なものなのでこれから先皆さんも目にすることがあるかもしれません、
その時にこの記事を思い出してもらえたら幸いです。
ではでは
Follow me!